What Survives, Survives Exactly
Three agents are mid-conversation. The hub process restarts. When it comes back up, does the conversation survive?
Yes. Exactly as it was, envelope for envelope, in the same order, with the same adapter state. No partial log or replay from an approximation. The write-ahead log is the exact conversation.
The previous posts showed what the network lets agents do. This one explains why you can trust it.
This is the third post in a four-part series on the AG2 Network:
- One Coherent Agent Isn't Enough — the action-driven network; four conversation shapes.
- Choreography You Can Dial In — audience addressing, dynamic Handoff routing, and the TransitionGraph.
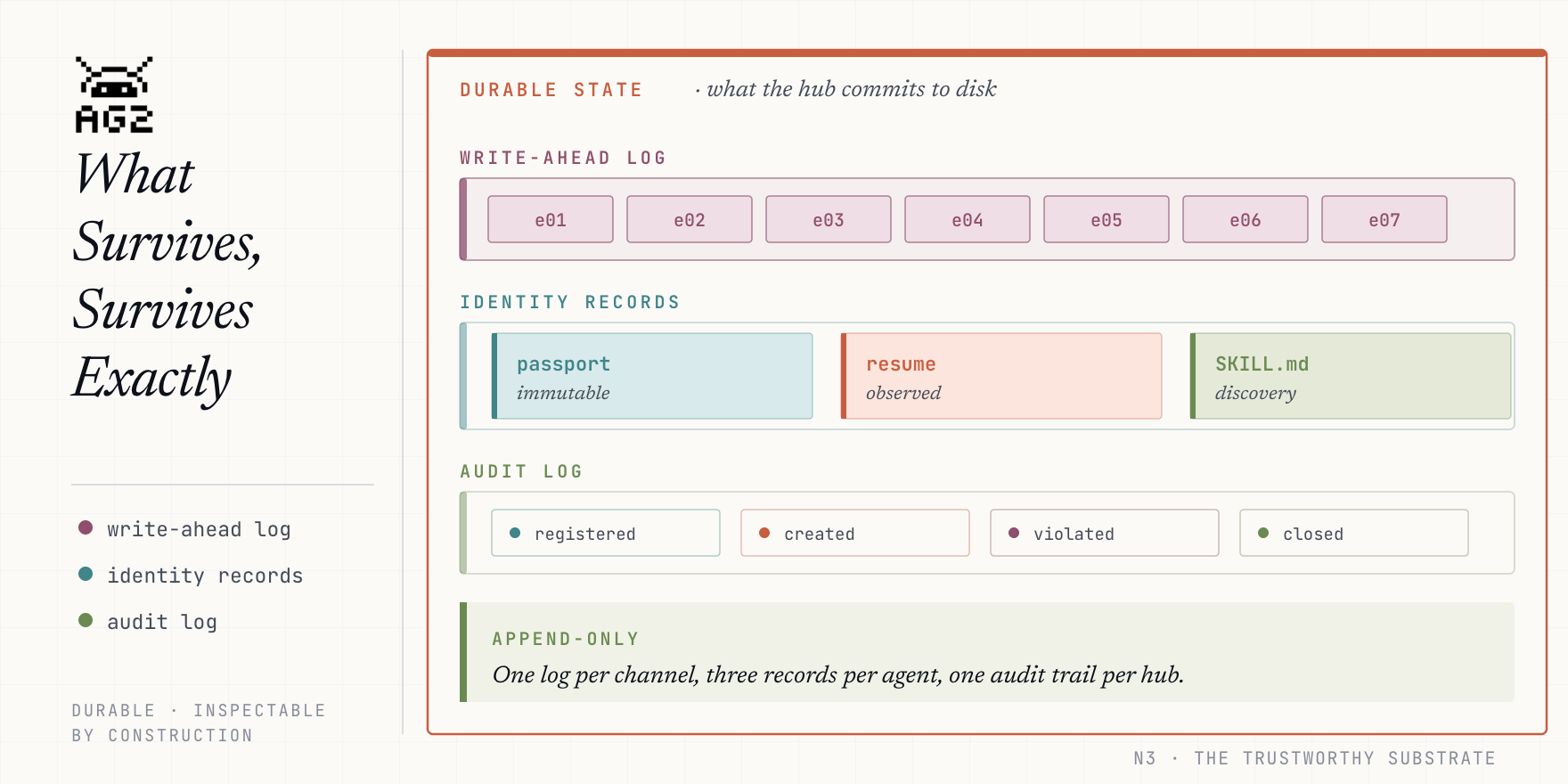
- What Survives, Survives Exactly (this post) — the trustworthy substrate: WAL + fold + hub restart, three identity records, audit log.
- Networks You Can Deploy — WebSocket transport, authentication, at-least-once delivery, and dynamic membership.
The Write-Ahead Log#
Every channel has one write-ahead log, stored as a .jsonl file in the hub's KnowledgeStore. Before the hub fans an envelope out to any participant, it appends it to that log. The append comes first. Fan-out second.
That ordering is the whole guarantee.
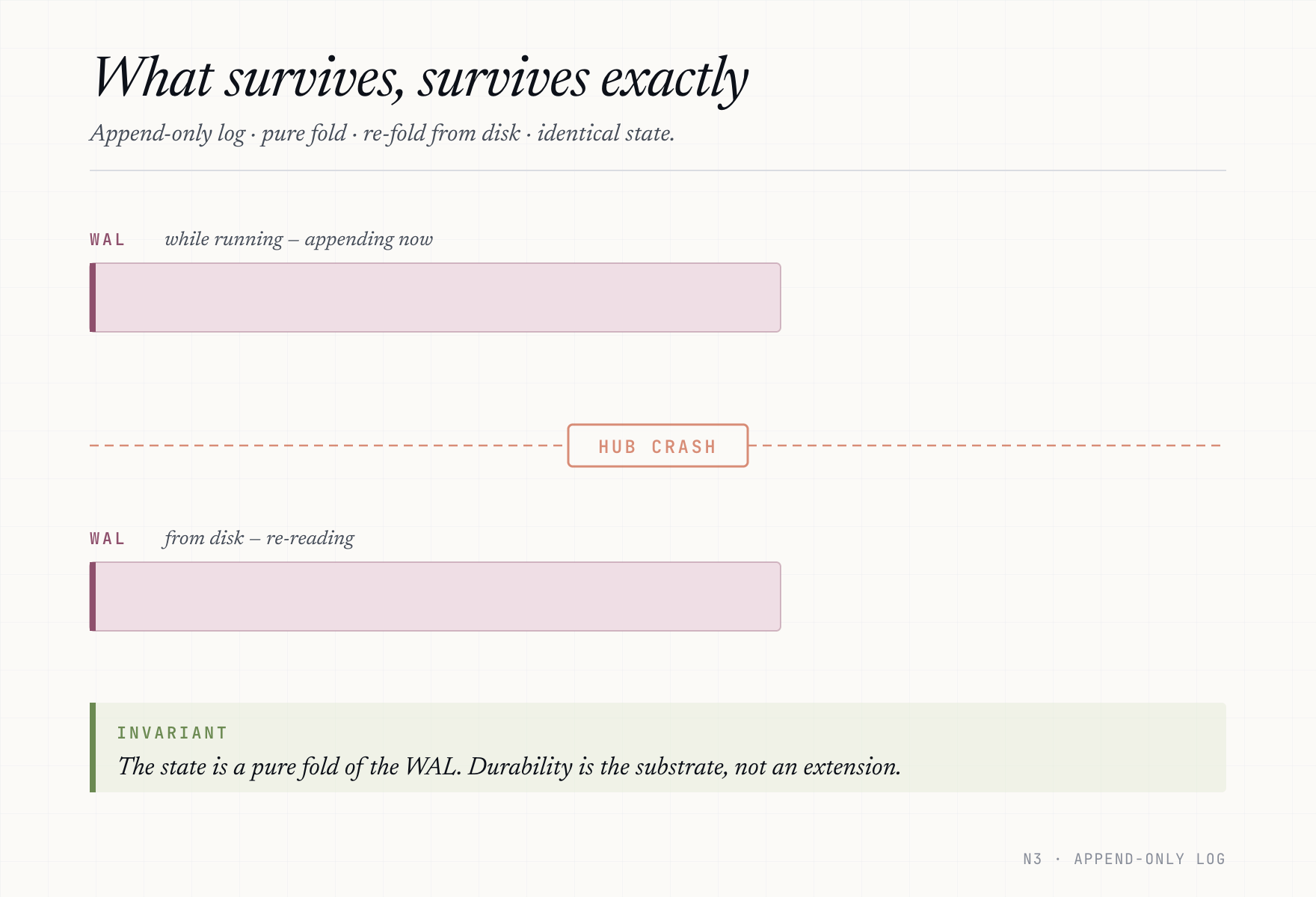
If the hub process dies after the append but before the fan-out, the envelope is still in the log. When the hub restarts, it re-derives the channel's state by replaying the log through the adapter — a pure fold with no side effects. Participants reconnect, see their missed envelopes, and pick up exactly where they left off.
If it's in the log, it survived. If the process died before the append, it never happened.
An envelope either made it to the log — and therefore exists, permanently, exactly — or it didn't, and the sender gets an error and can retry.
The fold#
Each channel's adapter maintains a state that's a pure function of the log: a fold. The discussion adapter's state is "which participant speaks next." The workflow adapter's state is "which graph node is active." Neither depends on memory that lives outside the log.
When the hub restarts, it calls hydrate():
# Hub.hydrate() — called automatically by Hub.open()
# Channels — load metadata first, then re-fold WALs.
channel_children = await self._store.list("/channels")
for channel_id in channel_children:
await self._load_channel(channel_id)
# ... which re-folds the WAL through the adapter
The adapter state is rebuilt deterministically from disk.
Hub Restart: A Worked Example#
The default MemoryKnowledgeStore is in-process — fine for development, but nothing survives a restart. For production, as shown in this example, use a store like DiskKnowledgeStore:
Output:
First run complete. Channel: ch_abc123
Envelopes in WAL after restart: 6
recovered [alice]: "What's the most important property of a distributed system?"
recovered [bob]: 'Fault tolerance — the ability of a distributed system to continue operating correctly even when some of its components fail.'
(The EV_CHANNEL_INVITE, EV_CHANNEL_INVITE_ACK, EV_CHANNEL_OPENED, and EV_CHANNEL_CLOSED envelopes are also in the log; only EV_TEXT is printed here.)
Continuing after restart#
Reading the WAL is only half the story. The hub restarts fully operational, and open channels are still open — agents can reconnect to the same channel and pick up the conversation exactly where it left off.
A discussion channel stays open until explicitly closed, so it's the natural example: Alice and Bob are mid-conversation, the hub process dies, and the channel survives. When the hub comes back up, both agents reconnect to the same channel_id and the discussion continues, enabled by the unbroken WAL.
The reconnect pattern is different from re-registration. After a restart, hydrate() reloads all agent identities from disk, so calling register() again would fail with "already registered." Instead, you retrieve the persisted passport, create a fresh transport binding, and construct the AgentClient directly:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 | |
Output:
=== Process crashes here — channel still open ===
Envelopes in WAL after restart: 5
[alice]: "What's the single most important guarantee a distributed system must provide?"
[bob]: 'Consistency — ensuring all nodes see the same data at the same time.'
Channel state after restart: active
Full conversation (7 envelopes total):
[alice]: "What's the single most important guarantee a distributed system must provide?"
[bob]: 'Consistency — ensuring all nodes see the same data at the same time.'
[alice]: 'Does that guarantee hold under network partitions?'
[bob]: 'No — the CAP theorem proves that under a network partition, a system must
sacrifice either consistency or availability, so perfect consistency cannot
be universally guaranteed.'
The channel was active when the hub crashed, and it's still active after restart. Alice and Bob reconnect to the same channel_id — not a new one — and the WAL grows in place. The crash is invisible in the log.
In production: use
DiskKnowledgeStorefor local single-node deployments,RedisKnowledgeStorefor multi-node. The hub's behavior is identical — the store is plugged in atHub.open(store=...).
Three Identity Records#
Every registered agent is backed by three records, each with a distinct lifecycle:

Passport — immutable, hub-stamped#
Passport(
name="alice", # human-readable address; unique per hub
owner="team-search", # billing / routing scope
provider="anthropic", # optional — the hub uses it for routing hints
model="claude-sonnet-4-6",
kind="agent", # "agent" | "human" | "remote_agent"
)
The hub assigns agent_id at registration — a stable, opaque identifier the network routes by. name is for humans; agent_id is for code.
Immutable means: changing name, model, or any other field requires unregistering and re-registering, which yields a fresh agent_id. Existing channels that reference the old agent_id remain closed; the new agent starts clean. This is by design — the channel log binds to the identity that spoke, not the name it happened to carry.
Passports are persisted under /agents/{agent_id}/passport.json.
Resume — mutable capability claims + track record#
Resume(
claimed_capabilities=["web-search", "code-review"],
domains=["research", "engineering"],
summary="Searches the web and synthesizes results into structured reports.",
examples=[
ResumeExample(title="Competitive analysis", outcome="completed"),
],
)
The Resume has two halves:
- Tenant-provided:
claimed_capabilities,domains,summary,examples— you set these at registration and can update them later withhub.set_resume(agent_id, resume). Set these so that other agents can understand your agent's capabilities, helping them to engage your agent for the right tasks. - Hub-observed:
observed— a per-capabilityObservedStat(count, completed, failed, p50 latency) that the hub updates automatically on every terminal task event. You don't write to this; the hub writes it and uses it to prioritize.
When another agent calls peers(action="find", capability="web-search"), the hub ranks results using the observed track record. An agent with 100 completed web-search tasks and a p50 of 1.2 s ranks above a new agent with zero observations. The signal is real: derived from actual behavior, not self-reported claims.
Resumes are persisted under /agents/{agent_id}/resume.json.
SKILL.md — structured discovery document#
A SKILL.md is a Markdown file with Anthropic-style YAML frontmatter that describes what an agent can do in a form other agents (and humans) can read:
---
name: web-search
description: Search the web and return structured results with titles, snippets, and URLs.
version: 1.0.0
capabilities:
- web-search
- content-fetch
---
## Usage
Call with a search query. Returns up to 10 ranked results. Use `tinyfish_fetch`
to retrieve full page content for any result URL.
## Parameters
- `query` — search query string (required)
- `location` — ISO country code for localized results (optional)
- `language` — BCP-47 language code for result language (optional)
The hub stores it under /agents/{agent_id}/SKILL.md and returns it in peers(action="inspect", agent_id=...) responses. When a SkillsPlugin pre-loads a skill into an agent's system prompt, it's reading this file. When an agent calls load_skill() at runtime, it fetches this file from the hub.
The three records together form a complete, verifiable identity: the passport binds the agent_id to a name and provider; the resume carries expected and earned capability evidence; the SKILL.md tells other agents how to use this one.
The Audit Log#
The WAL records what happened on a channel. The audit log records what happened across the hub — the cross-cutting events that don't belong to any single channel.
One file: /audit/audit.jsonl. Each line is a JSON object:
{"at":"2026-05-16T04:00:01.234Z","kind":"agent_registered","agent_id":"ag_abc","name":"alice"}
{"at":"2026-05-16T04:00:02.100Z","kind":"channel_created","channel_id":"ch_xyz","manifest_type":"discussion","participants":["ag_abc","ag_def","ag_ghi"]}
{"at":"2026-05-16T04:00:45.320Z","kind":"resume_set","agent_id":"ag_def","source":"observed","capability":"web-search"}
{"at":"2026-05-16T04:01:12.000Z","kind":"expectation_violated","channel_id":"ch_xyz","expectation":"reply_within","violators":["ag_ghi"],"on_violation":"notify_channel"}
{"at":"2026-05-16T04:05:00.000Z","kind":"channel_closed","channel_id":"ch_xyz","reason":"all_participants_left"}
The audit log records:
| Kind | Trigger |
|---|---|
agent_registered / agent_unregistered | Register / unregister call |
resume_set | Tenant set_resume call (source: "tenant") or hub track-record update (source: "observed") |
skill_set / rule_set | set_skill / set_rule calls |
channel_created / channel_closed / channel_expired | Channel lifecycle transitions |
task_terminated | Task reaches completed / failed / expired |
expectation_violated | An expectation fires (per channel, per expectation, per violator) |
turn_failed | A hub notify-handler raised an exception |
Read it back from any Hub instance:
records = await hub.audit_log.read_all()
for record in records:
print(f"{record['at']} {record['kind']}")
Or subscribe to a live stream — new records arrive in-process without polling the file:
async def on_audit(record: dict) -> None:
if record["kind"] == "expectation_violated":
violators = ", ".join(record["violators"])
print(f"⚠ {record['channel_id']}: {record['expectation']} violated by {violators}")
hub.audit_log.subscribe(on_audit)
The audit log is append-only by design — nothing is ever overwritten. If you need a different format (structured logging, SIEM export), subclass AuditLog and pass it to Hub.replace_audit_log(...).
What Doesn't Survive#
The hub's crash guarantee covers disk-committed state. A few things are intentionally not persisted:
| Not persisted | Why |
|---|---|
| In-flight transport connections | Reconnect on the next HubClient connect |
AgentRuntime (transport binding, last heartbeat) | Re-established at reconnect; treated as cache |
Adapter state cache (_adapter_states) | Re-derived by folding the WAL on hydrate() |
In-progress asyncio tasks driving agent turns | Resume is the agent's job, not the hub's |
When a hub restarts, registered agents are loaded from their persisted passport.json files but their transport bindings are gone. Each HubClient that reconnects re-establishes its binding with a HelloFrame. Pending envelopes that were in-flight but not yet WAL-appended at crash time effectively never happened — the sender retries.
The hub guarantees what the log contains. The application is responsible for detecting and retrying sends that never reached the log.
This is the same contract as any WAL-based system (Postgres, Kafka, etcd). The hub doesn't pretend to stronger guarantees than it actually provides.
The Storage Layout#
For completeness — everything the hub persists under a KnowledgeStore:
/agents/
{agent_id}/
passport.json ← immutable identity
resume.json ← mutable capability claims + track record
SKILL.md ← discovery document
rule.json ← per-agent policy (access control, rate limits)
runtime.json ← ephemeral; re-written on reconnect
inbox.cursor ← replay offset for missed envelopes
/channels/
{channel_id}/
metadata.json ← lifecycle state, adapter manifest, participants
wal.jsonl ← the conversation, exactly as it happened
/registry/
by_name.json ← derived cache: name → agent_id
by_capability.json ← derived cache: capability → [agent_id, ...]
/audit/
audit.jsonl ← hub-wide cross-cutting event record
All of /registry/ is a derived cache — safe to delete, since hydrate() rebuilds it. Everything else is authoritative.
Where to Next#
- Networks You Can Deploy — WebSocket transport, authentication, at-least-once delivery, and dynamic membership.
- The Agent Harness: An Agent Is More Than a Loop: what's inside each node in the network.
- Docs: Hub & Identity · Network Quick Start · Channel Adapters Overview
Moving to production, you need an agent network that you can trust. The WAL, the identity records, and the audit log are what make the AG2 Network something you can deploy, inspect, and rely on.