The Agent Harness: An Agent Is More Than a Loop

Today we're diving into the AG2 agent, it's harness, as this plays a crucial role in having a reliable long-term agent.
An agent has moved on from a simple loop around LLM and tool calls. It has memory that spans thousands of turns. It can run tools in parallel, delegate subtasks, and call back to a human. It keeps producing under context pressure. It can be traced, metered, and gated. This post zooms in on that machinery — what the AG2 beta harness gives you, and how to reach for each part.
This is the companion post to the AG2 Network series:
- One Coherent Agent Isn't Enough — the action-driven multi-agent network.
- Choreography You Can Dial In — expectations, audience addressing, deeper choreography.
- What Survives, Survives Exactly — WAL, identity, audit.
- Networks You Can Deploy — federation, dynamic membership, production incident (coming soon).
- The Agent Harness (this post) — what lives inside each node: stream, assembly, middleware, tools, observers, HITL, and memory.
The Harness#
The Agent class in autogen.beta is a thin coordinator. It stitches together six independently-pluggable layers:
| Layer | Role |
|---|---|
| MemoryStream | The append-only backbone. Every event — user messages, model responses, tool calls, results — lands here first. |
| AssemblyPolicy | Rebuilds the context window before each LLM call, applying compaction and aggregation so the agent stays useful under context pressure. |
| Middleware | Four call sites: on_turn, on_llm_call, on_tool_execution, on_human_input. The stack wraps each operation — tracing, auth, rate limiting all live here. |
| Tools | Callables decorated with @tool (or Toolkit instances). Provider-agnostic schema, parallel execution. |
| Observers | Read-only window onto the event stream. TokenMonitor and LoopDetector ship out of the box; write your own in 10 lines. |
| Knowledge | Persistent key-value storage that survives process restarts. MemoryKnowledgeStore for dev and tests, SqliteKnowledgeStore for prod. |
Each layer is a Protocol with a sensible default. You only reach for a layer when you need to change its behavior.
MemoryStream — the event backbone#
Every turn starts here. The MemoryStream is a typed, append-only log of BaseEvent subclasses:
from autogen.beta import Agent
from autogen.beta.config import OpenAIConfig
agent = Agent(
"assistant",
prompt="You are a helpful assistant.",
config=OpenAIConfig(model="gpt-4o-mini"),
)
reply = await agent.ask("What is 2 + 2?")
print(await reply.content())
# Read the full event history from the reply
for event in await reply.history.get_events():
print(type(event).__name__, getattr(event, "content", "")[:60])
The stream emits events in the order they occurred: ModelRequest, ModelResponse, ToolCallEvent, ToolResultEvent, HumanInputRequest, HumanMessage. Observers (covered below) and assembly both read from the same stream.
Try it live: open the Agent Ask demo in the AG2 Playground — start a turn with
Agent.ask(), continue it withAgentReply.ask(), and watch each event stream in token by token.
AssemblyPolicy — surviving context pressure#
Assembly is what happens before the LLM call. An AssemblyPolicy reads the event stream and produces the list of messages the LLM actually sees. The default policy replays every message from the stream. You override it — and add Compact and Aggregate strategies — when the conversation grows longer than the model's context window.
Try it live: open the Context Lens demo in the AG2 Playground — toggle
ConversationPolicy/SlidingWindowPolicy/TokenBudgetPolicyand watch the LLM's view diverge from the raw stream in real time.
Compaction: drop history, keep the gist#
Compaction strategies live on the KnowledgeConfig and fire when a CompactTrigger threshold is crossed. The cheapest strategy, TailWindowCompact(target=N), keeps the last N events and drops the rest — zero LLM cost:
from autogen.beta import Agent, KnowledgeConfig
from autogen.beta.compact import CompactTrigger, TailWindowCompact
from autogen.beta.config import OpenAIConfig
from autogen.beta.knowledge import MemoryKnowledgeStore
agent = Agent(
"assistant",
prompt="You are a helpful assistant.",
config=OpenAIConfig(model="gpt-4o-mini"),
knowledge=KnowledgeConfig(
store=MemoryKnowledgeStore(),
compact=TailWindowCompact(target=10), # keep the last 10 events
compact_trigger=CompactTrigger(max_events=40), # fire once history passes 40 events
),
)
Once the stream passes 40 events, compaction fires: the history is trimmed to the last 10 events and the dropped span is written to the store's log, so nothing is lost. When you want the gist kept in context rather than just archived, swap in SummarizeCompact(target=10, config=...) — it spends one LLM call to replace the dropped span with a single CompactionSummary event at the head of the history, so the summary is part of the durable record.
Try it live: open the Compaction Cycle demo in the AG2 Playground — run
TailWindowCompactandSummarizeCompactover the same conversation side by side; watch the trigger fire, events drop, and the synthesised summary appear.
Aggregation: accumulate knowledge across turns#
Where compaction discards history in favour of a gist, aggregation accumulates structured knowledge to a persistent store. ConversationSummaryAggregate extracts a running summary; WorkingMemoryAggregate maintains a key/value memory the agent consults on every turn:
from autogen.beta import Agent, KnowledgeConfig
from autogen.beta.aggregate import AggregateTrigger, WorkingMemoryAggregate
from autogen.beta.config import OpenAIConfig
from autogen.beta.knowledge import MemoryKnowledgeStore
from autogen.beta.policies import WorkingMemoryPolicy
agent = Agent(
"assistant",
prompt="You are a helpful research assistant. Consult your working memory before answering.",
config=OpenAIConfig(model="gpt-4o-mini"),
knowledge=KnowledgeConfig(
store=MemoryKnowledgeStore(),
aggregate=WorkingMemoryAggregate(config=OpenAIConfig(model="gpt-4o-mini")),
aggregate_trigger=AggregateTrigger(every_n_turns=5),
),
assembly=[WorkingMemoryPolicy()],
)
Every 5 turns the aggregator runs, extracts key facts from the conversation, and writes them to /memory/working.md in the KnowledgeStore. On the next turn the WorkingMemoryPolicy in the assembly=[...] chain reads that file and prepends the working memory to the context window — so the agent "remembers" facts across compaction boundaries, and across process restarts when the store is persistent.
Try it live: open the Working Memory demo in the AG2 Playground —
WorkingMemoryAggregatewrites/memory/working.mdafter every turn; a brand-new Agent in session 2 gets it injected byWorkingMemoryPolicyand remembers.
Middleware — four call sites#
The middleware stack wraps every operation with call_next semantics, familiar from HTTP middleware (FastAPI, Django, etc.). Override only the hooks you need:
from collections.abc import Awaitable, Callable, Sequence
from autogen.beta.annotations import Context
from autogen.beta.events import BaseEvent, ModelResponse, ToolCallEvent, ToolResultEvent, ToolErrorEvent, ClientToolCallEvent
from autogen.beta.middleware.base import BaseMiddleware, AgentTurn, LLMCall, ToolExecution
ToolResultType = ToolResultEvent | ToolErrorEvent | ClientToolCallEvent
class TracingMiddleware(BaseMiddleware):
async def on_turn(
self,
call_next: AgentTurn,
event: BaseEvent,
context: Context,
) -> ModelResponse:
print(f"→ turn start")
response = await call_next(event, context)
print(f"← turn end ({response.content[:40]}…)")
return response
async def on_llm_call(
self,
call_next: LLMCall,
events: Sequence[BaseEvent],
context: Context,
) -> ModelResponse:
print(f" LLM called with {len(events)} events in context")
return await call_next(events, context)
async def on_tool_execution(
self,
call_next: ToolExecution,
event: ToolCallEvent,
context: Context,
) -> ToolResultType:
print(f" tool: {event.name}({event.arguments})")
result = await call_next(event, context)
print(f" result: {str(result)[:40]}…")
return result
Register middleware at construction time:
from autogen.beta import Agent, Middleware
from autogen.beta.config import OpenAIConfig
agent = Agent(
"assistant",
prompt="You are a helpful assistant.",
config=OpenAIConfig(model="gpt-4o-mini"),
middleware=[Middleware(TracingMiddleware)],
)
The Middleware(cls, **kwargs) wrapper is a factory: a new BaseMiddleware instance is created per turn so state is naturally turn-scoped. The four hooks are independent — on_turn wraps the whole turn, on_llm_call wraps only the model call, on_tool_execution wraps each tool in isolation, and on_human_input wraps the human-input checkpoint.
Built-in middleware#
AG2 ships TelemetryMiddleware (OpenTelemetry traces, spans, LLM semantic attributes) and LoggingMiddleware out of the box, plus history limiters — HistoryLimiter caps the history by event count, and TokenLimiter caps it by a token budget, trimming the conversation to fit before each call:
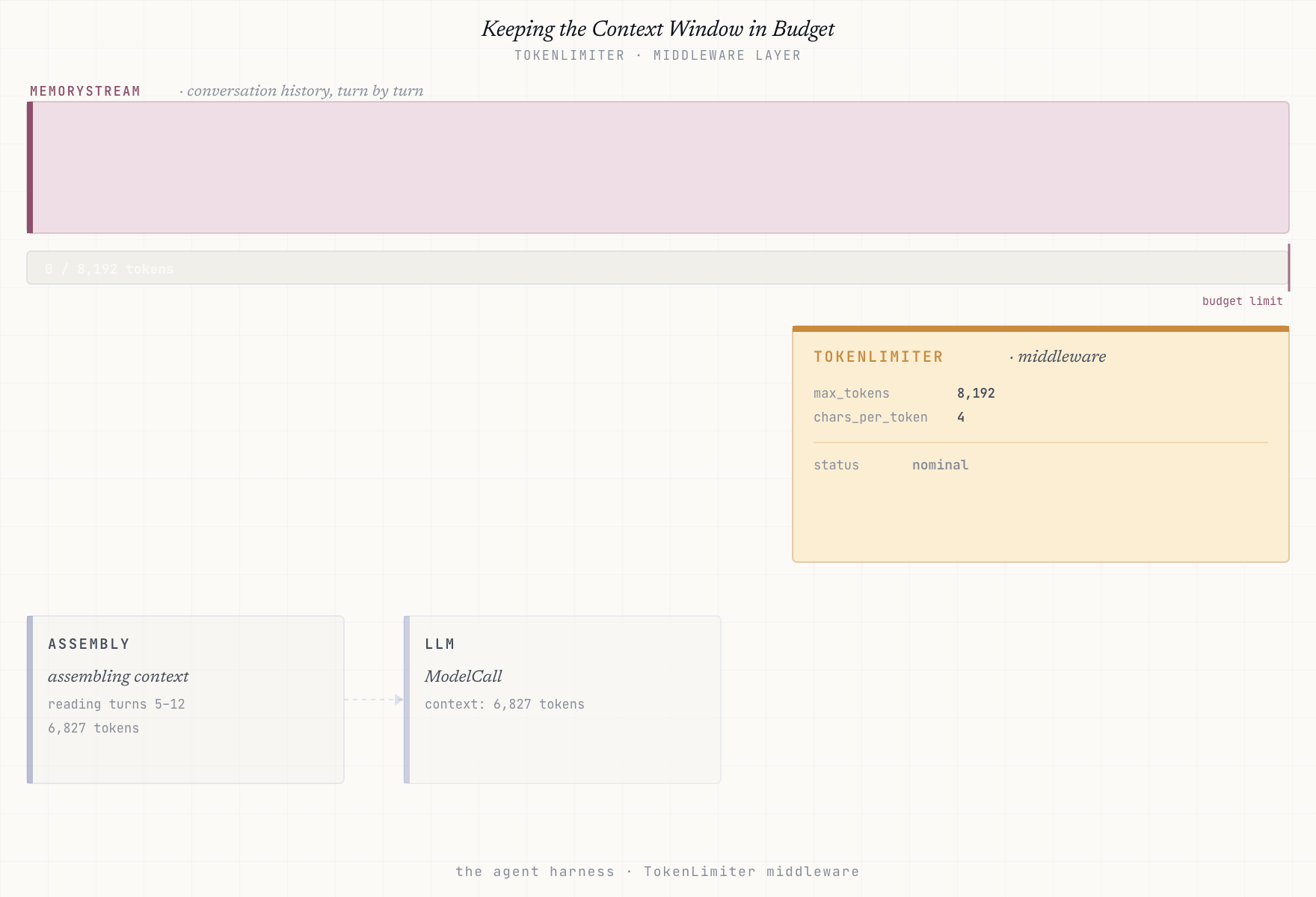
See the middleware docs for the full reference.
Try it live: open the Middleware Stack demo in the AG2 Playground — watch
LoggingMiddleware,RetryMiddleware, andHistoryLimiterwrap a Beta Agent as a retry recovers from a fault and history is trimmed before the model call.
Tools — @tool, Toolkit, subagent delegation#
Tools are the primary way agents extend their capabilities. The @tool decorator converts a plain function into a provider-neutral schema that works across LLM provider:
from autogen.beta import Agent, tool
from autogen.beta.config import OpenAIConfig
@tool
def get_weather(city: str) -> str:
"""Return the current weather for a city (demo: always sunny)."""
return f"It is sunny in {city} today."
agent = Agent(
"weather_bot",
prompt="Answer weather questions. Use the provided tool.",
config=OpenAIConfig(model="gpt-4o-mini"),
tools=[get_weather],
)
reply = await agent.ask("What's the weather in Tokyo?")
Try it live: open the Ask the Web demo in the AG2 Playground — a single Beta Agent uses Tavily search and fetch to answer with inline citations and live source cards, streamed over the AG-UI protocol.
Toolkit — group related tools#
Toolkit bundles related tools into one object. A factory function is the simplest way to build one — the tools share construction-time state (here user_id) through a closure, keeping their signatures clean:
from autogen.beta import Agent, Toolkit, tool
from autogen.beta.config import OpenAIConfig
def calendar_toolkit(user_id: str) -> Toolkit:
@tool
def list_events(date: str) -> list[str]:
"""List calendar events for a date (YYYY-MM-DD)."""
return [f"Meeting at 10am on {date}"]
@tool
def add_event(date: str, title: str) -> str:
"""Add a calendar event."""
return f"Added '{title}' on {date} for user {user_id}"
return Toolkit(list_events, add_event, name="calendar")
agent = Agent(
"calendar_bot",
prompt="Help the user manage their calendar.",
config=OpenAIConfig(model="gpt-4o-mini"),
tools=[calendar_toolkit(user_id="u123")],
)
For richer toolkits you can subclass Toolkit and pass the tools to super().__init__(*tools) — that's how the built-in FilesystemToolkit exposes read_file, write_file, and friends.
Subagent delegation#
For tasks that need a separate conversation thread — a research pass, a code review, a long-running subtask — wrap a dedicated agent as a tool with Agent.as_tool(). The wrapped agent runs on its own stream and returns its result as the tool's output:
from autogen.beta import Agent
from autogen.beta.config import OpenAIConfig
researcher = Agent(
"researcher",
prompt="You are a thorough research assistant. Synthesise in 3 bullet points.",
config=OpenAIConfig(model="gpt-4o-mini"),
)
orchestrator = Agent(
"orchestrator",
prompt="Answer questions by delegating research to the researcher tool.",
config=OpenAIConfig(model="gpt-4o-mini"),
tools=[
researcher.as_tool(description="Research a topic and synthesise the findings"),
],
)
as_tool exposes the researcher as a callable named task_researcher; when the orchestrator invokes it, the subagent runs in isolation and its reply is injected back as the tool result — no manual asyncio.gather or result wiring needed. When you'd rather the framework inject the delegation tools for you, construct the agent with tasks=TaskConfig(...) to gain run_subtask / run_subtasks(parallel=True) automatically.
Try it live: open the Parallel Research demo in the AG2 Playground — a lead Beta agent fans out to three specialist subagents running in parallel, with live per-researcher progress lanes and a synthesised cited report.
Observers — read-only window onto events#
Observers see every event on the stream after it's committed. They're the right place for monitoring, alerting, and auditing — anything that reads but doesn't change the agent's control flow.
TokenMonitor#
Emit a warning at 50k tokens and a critical alert at 100k:
from autogen.beta import Agent
from autogen.beta.config import OpenAIConfig
from autogen.beta.observers import TokenMonitor
agent = Agent(
"assistant",
prompt="You are a helpful assistant.",
config=OpenAIConfig(model="gpt-4o-mini"),
observers=[TokenMonitor(warn_threshold=50_000, alert_threshold=100_000)],
)
When a threshold is crossed the monitor emits an ObserverAlert onto the stream. React to it with a tiny @observer(ObserverAlert) that runs on each one:
from autogen.beta import observer
from autogen.beta.events import ObserverAlert
@observer(ObserverAlert)
async def report_alerts(event: ObserverAlert) -> None:
print(f"[{event.severity}] {event.message}")
LoopDetector#
Fire an alert when the same tool is called with the same arguments three times in a row:
from autogen.beta import Agent, tool
from autogen.beta.config import OpenAIConfig
from autogen.beta.observers import LoopDetector
@tool
def search(query: str) -> str:
"""Search the web (demo)."""
return "no results"
agent = Agent(
"tool_agent",
prompt="Complete the task using the provided tools.",
config=OpenAIConfig(model="gpt-4o-mini"),
tools=[search],
observers=[LoopDetector(window_size=10, repeat_threshold=3)],
)
Writing your own#
The @observer(EventType) decorator pairs an event condition with a callback — the function runs once per matching event:
from autogen.beta import observer
from autogen.beta.events import ToolCallEvent
@observer(ToolCallEvent)
async def audit_tools(event: ToolCallEvent) -> None:
print(f"audit: tool={event.name} args={event.arguments}")
Human-in-the-loop (HITL)#
Human approval checkpoints interrupt the turn at a predictable point — after the LLM decides to call a tool, before the call executes. The simplest route is the built-in approval_required() tool middleware: it pauses the tool and calls context.input(), which the agent's hitl_hook answers. Approve by returning the human's reply; deny by raising HumanInputNotProvidedError:
from autogen.beta import Agent, tool
from autogen.beta.config import OpenAIConfig
from autogen.beta.middleware import approval_required
@tool(middleware=[approval_required()])
def delete_record(record_id: str) -> str:
"""Delete a record (requires human approval)."""
return f"Record {record_id} deleted."
def approve(request) -> str:
# `request.content` holds the approval prompt; return the human's answer.
return input(f"{request.content} ")
agent = Agent(
"admin_bot",
prompt="You are an admin assistant. Confirm destructive operations.",
config=OpenAIConfig(model="gpt-4o-mini"),
tools=[delete_record],
hitl_hook=approve,
)
The HumanInputRequest event lands in the stream before the human answer, so the approval decision is part of the durable record — whether the agent runs locally or inside a network node. For full control over routing (a web UI, Slack, a queue), implement the on_human_input middleware hook instead and answer the HumanInputRequest there.
KnowledgeStore — persistence across restarts#
Agents write to a KnowledgeStore for anything that should outlive a process restart: aggregated memory, downloaded files, cached tool results. Four stores ship today:
| Store | When to use |
|---|---|
MemoryKnowledgeStore | Tests, single-process demos. Wiped on exit. |
SqliteKnowledgeStore | Single-host production. Zero dependencies. |
DiskKnowledgeStore | When you want file-system transparency (and watchdog installed). |
RedisKnowledgeStore | Multi-process deployments or when you need TTL. |
Swap the store without touching the agent:
from autogen.beta import Agent, KnowledgeConfig
from autogen.beta.aggregate import AggregateTrigger, WorkingMemoryAggregate
from autogen.beta.config import OpenAIConfig
from autogen.beta.knowledge import SqliteKnowledgeStore
agent = Agent(
"assistant",
prompt="You are a helpful assistant with persistent memory.",
config=OpenAIConfig(model="gpt-4o-mini"),
knowledge=KnowledgeConfig(
store=SqliteKnowledgeStore("./agent_memory.db"),
aggregate=WorkingMemoryAggregate(config=OpenAIConfig(model="gpt-4o-mini")),
aggregate_trigger=AggregateTrigger(every_n_turns=5),
),
)
Files saved to knowledge via FilesAPI (photos, docs, audio) are addressed by path and survive the same store swap — a file uploaded via MemoryKnowledgeStore in tests and SqliteKnowledgeStore in production is the same API call.
Try it live: the Working Memory demo in the AG2 Playground shows the persistence payoff end to end — what one session writes to the store, a brand-new Agent in the next session reads back.
Putting it together#
A minimal production-ready agent with token monitoring, loop detection, compaction, and persistent memory:
import asyncio
from autogen.beta import Agent, KnowledgeConfig, observer, tool
from autogen.beta.aggregate import AggregateTrigger, WorkingMemoryAggregate
from autogen.beta.compact import CompactTrigger, TailWindowCompact
from autogen.beta.config import OpenAIConfig
from autogen.beta.events import ToolCallEvent
from autogen.beta.knowledge import SqliteKnowledgeStore
from autogen.beta.observers import LoopDetector, TokenMonitor
@observer(ToolCallEvent)
async def audit(event: ToolCallEvent) -> None:
print(f"AUDIT tool={event.name}")
@tool
def search_docs(query: str) -> str:
"""Search the documentation."""
return f"Results for '{query}': (demo)"
async def main():
agent = Agent(
"prod_assistant",
prompt="You are a helpful assistant with long-term memory.",
config=OpenAIConfig(model="gpt-4o-mini"),
tools=[search_docs],
knowledge=KnowledgeConfig(
# Persistent store — survives process restarts
store=SqliteKnowledgeStore("./memory.db"),
# Compaction strategy: keep the last 10 events verbatim
compact=TailWindowCompact(target=10),
# Run compaction once history passes 40 events
compact_trigger=CompactTrigger(max_events=40),
# Aggregation strategy: distil the session into working memory
aggregate=WorkingMemoryAggregate(config=OpenAIConfig(model="gpt-4o-mini")),
# Run aggregation every 5 turns
aggregate_trigger=AggregateTrigger(every_n_turns=5),
),
observers=[
# Warn at 30k tokens in context, alert at 80k
TokenMonitor(warn_threshold=30_000, alert_threshold=80_000),
# Alert when the same tool call repeats 3 times in a row
LoopDetector(repeat_threshold=3),
# Custom observer (defined above) — logs every tool call
audit,
],
)
while True:
user_input = input("You: ")
if not user_input:
break
reply = await agent.ask(user_input)
print(f"Agent: {await reply.content()}")
asyncio.run(main())
Each component is pluggable and independently testable — the observers don't affect compaction, compaction doesn't affect aggregation, and replacing SqliteKnowledgeStore with MemoryKnowledgeStore makes any test hermetic.
What's next?#
Start building your own agent - AG2's Agent harness provides the components for you to build robust and long-running agents. Reach out to the friendly community and maintainers on Discord if you need help.