AutoGen Studio: Interactively Explore Multi-Agent Workflows
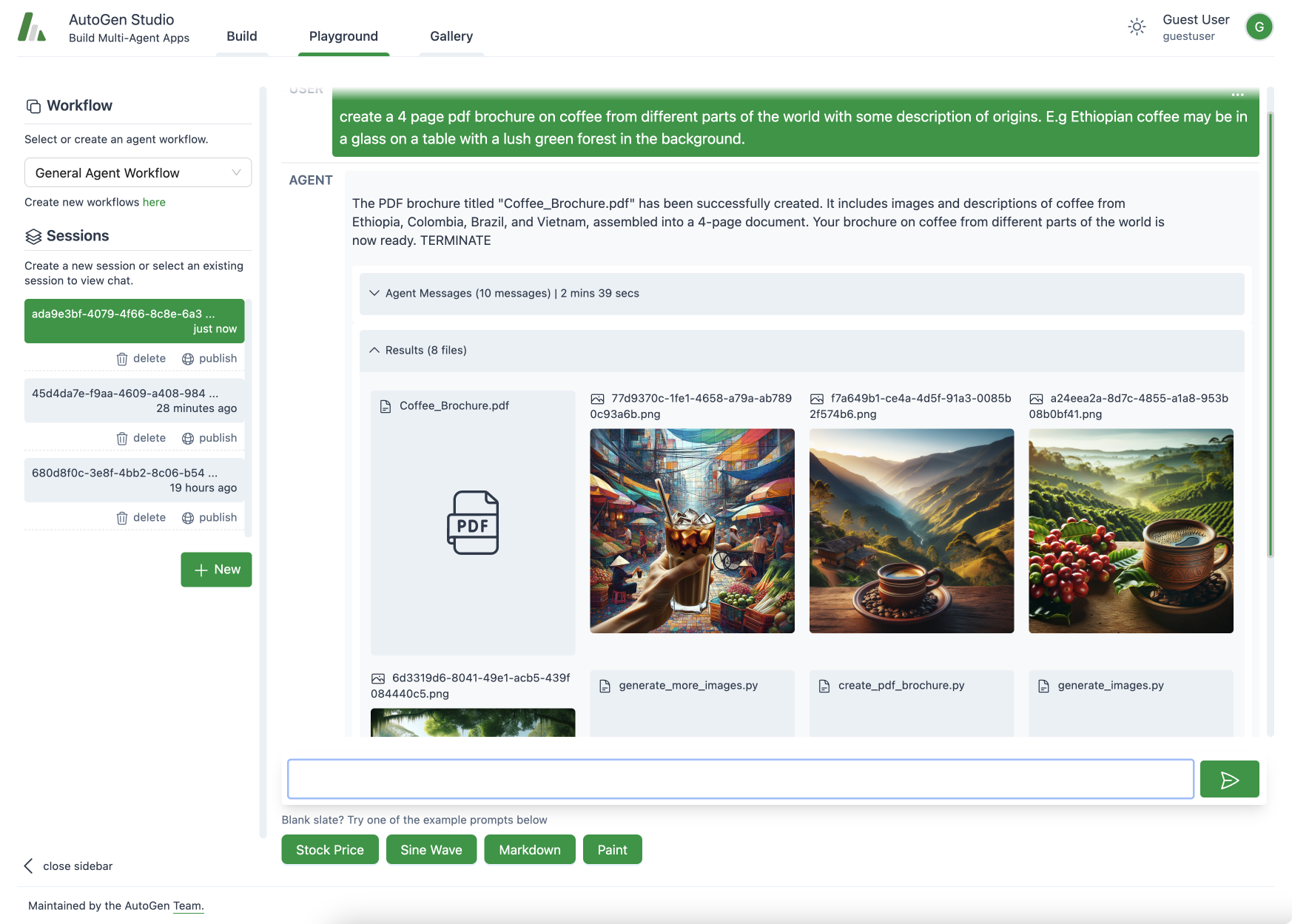
AutoGen Studio: Solving a task with multiple agents that generate a pdf document with images.
TL;DR
To help you rapidly prototype multi-agent solutions for your tasks, we are introducing AutoGen Studio, an interface powered by AutoGen. It allows you to:
- Declaratively define and modify agents and multi-agent workflows through a point and click, drag and drop interface (e.g., you can select the parameters of two agents that will communicate to solve your task).
- Use our UI to create chat sessions with the specified agents and view results (e.g., view chat history, generated files, and time taken).
- Explicitly add skills to your agents and accomplish more tasks.
- Publish your sessions to a local gallery.
See the official AutoGen Studio documentation for more details.
AutoGen Studio is open source code here, and can be installed via pip. Give it a try!
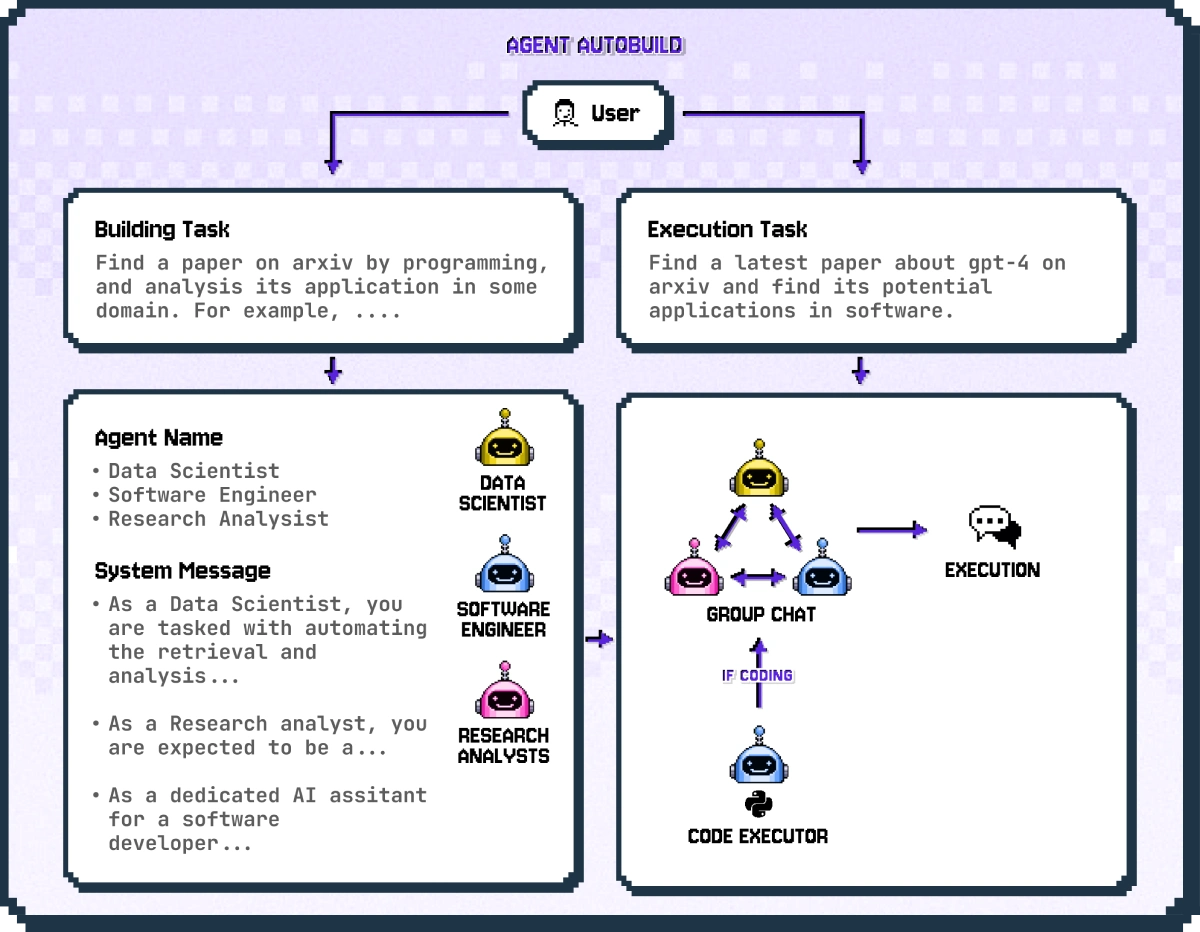
 TL;DR:
TL;DR: